

Tabla de contenido:
Una de las principales ventajas de tener un proyecto alterno o side project y como he podido evidenciar a lo largo del desarrollo de un emulador de la consola de videojuegos más importante de los años 80 la NES (Nintendo Enterteinment System), ha sido la libertad de experimentar nuevas tecnologías o estrategias que quizás en una empresa o compañia para la cual trabajemos no tendremos esa oportunidad. Cuando decidí construir este emulador de la NES dos de las razones más importantes que tuve presente fueron: (1) Aprender sobre la metodología TDD (Test Driven Development) y (2) conocer sobre la arquitectura de un hardware que representó mucho para mi infancia (por más que en ese entonces solo pude tener acceso a una consola clon de la NES 😉.
Por aquel entonces cuando decidí iniciar con la construcción de este proyecto muy ambicioso en lo que a mi respecta, el mayor problema al que me enfrentaba era el casi nulo conocimiento sobre la arquitectura interna del hardware de la consola, y mayor aún como iba a abstraer a software esta complejidad de tal manera que pueda lograr el objetivo de realizar la emulación de su hardware al completo. Si bien he tenido la experiencia de conocer sobre la arquitectura de computadores a bajo nivel en un momento de mi vida cuando realizaba ingeniería inversa a software para el sistema operativo Windows, este tipo de conocimiento e interés que ya tenía (y aún sigo teniendo) sobre las cosas de bajo nivel, como leer montón de código ensamblador en un depurador o desensamblador de binarios, me permitía conocer sobre el funcionamiento real de las cosas (software), como lo era, un sistema de protección determinado y encontrar la manera de sobrepasarlo. Por esta razón se sumaba al proyecto un interés genuino por conocer como esta NES funcionaba y hacía las cosas que nos brindaron mucha diversión en la infancia.
 Nintendo Entertainment System (NES) - Imagen obtenida de https://unsplash.com/es/fotos/consola-snes-clasica-ZV7lnfyQLmA
Nintendo Entertainment System (NES) - Imagen obtenida de https://unsplash.com/es/fotos/consola-snes-clasica-ZV7lnfyQLmA
Una arquitectura moderna de procesadores como las que debía conocer por allá entre los años 2007 y 2015, por más que el poder de cómputo no se compara con los procesadores actuales, siguen estando basados en la arquitectura moderna x86 y x86_64 que se emplean mayormente a día de hoy para computadoras domésticas. Este tipo de arquitectura difiere totalmente a una arquitectura de procesadores empleadas por ejemplo para este caso la NES y es aquí donde la metodología TDD hace su protagonismo, al brindarme según su filosofía la capacidad de abstraer la complejidad de un desarrollo de software, dividiéndolo en pequeñas partes que se hacen mucho más manejables y entendibles para las necesidades del proyecto.
Con la aplicación de TDD como metodología base de este proyecto hemos podido desatarnos de la complejidad que conlleva todo el sistema de hardware de la NES y nos ha permitido enfocarnos en componentes mas pequeños que podamos aprender y abstraer a los dominios del lenguaje Javascript para lograr su emulación. Todo esto enmarcado en un entorno de validación por pruebas de código que nos darán una confianza basadas en la premisa: Mientras el ¿Qué? (la prueba) esté bien, el ¿Cómo? (la implementación) pasará a un segundo plano e irá evolucionando y mejorando (Refactorización) con el paso del tiempo, resumiendo así de manera diferente a como se encuentra normalmente en los textos que hablan sobre TDD el ciclo principal de esta metodología, donde las pruebas de código toman el papel principal y guían el desarrollo y la abstracción de la complejidad de un sistema determinado, en nuestro caso la emulación de la NES.
La capacidad que nos brinda TDD de centrarnos en un problema particular mucho más pequeño, nos brindó el beneficio de preocuparnos por un problema determinado al tiempo y no toda la complejidad que conlleva la arquitectura de la NES. Cuando se puso en marcha el proyecto el primer componente que empecé a implementar fue la CPU (Central Processing Unit) o unidad de procesamiento central de la NES. Previamente excavé en la documentación que había al respecto sobre dicha arquitectura y como esta pieza en particular funciona, encontrando múltiples recursos, entre ellos la grandiosa NESDev Wiki, que me ofrecía un amplio vistazo general sobre los componentes e información necesaria acerca del funcionamiento de esta arquitectura. Una vez comprendido de manera general como funcionaba el componente en cuestión (la CPU) y los aspectos más relevantes a tener en cuenta, como su juego de instrucciones y su interacción con otros componentes, era ya el momento de poner todo sobre la mesa y centrarnos aproximar su implementación, y lo llamo aproximar porque en primera instancia tenemos una visión de la solución que muy probablemente difiera con la que tendremos más adelante.
El ejercicio consiste en construir un caso de prueba que nos valide el comportamiento que debe tener ese componente en cuestión bajo prueba o (Component Under Test) una variación del término SUT (System Under Test) de tal manera que nos despreocupamos de cómo este comportamiento será implementado, prestando excesiva atención al comportamiento que esté tendrá, o dicho de otra manera la interfaz pública que este ofrecerá al mundo exterior (API). Posteriormente una vez tenemos una aproximación con sentido de lo que esperamos de nuestro componente descrito en su prueba de código, procedemos a realizar la implementación que satisfaga dichos contratos y aserciones. Aquí quiero hacer énfasis en una de las leyes de TDD que predica, “No debemos escribir código de producción más que el necesario para que la prueba pase”. Es aquí donde a mi manera de verlo se comete uno de los principales errores a la hora de implementar TDD como metodología y que al principio me ví también muy tentado a caer, y es porque creemos tener la certeza que mientras escribimos este código de implementación, ha venido a nuestra mente la solución definitiva para este y otros aspectos hipotéticos fuera del componente bajo prueba que quizás sea necesario escribir ahora, pero la realidad nos dirá que no es así y más aún si nos aferramos a las 3 leyes básicas de esta metodología, ellas mismas nos darán la razón con el paso del tiempo y a medida que nuestro código base crece.
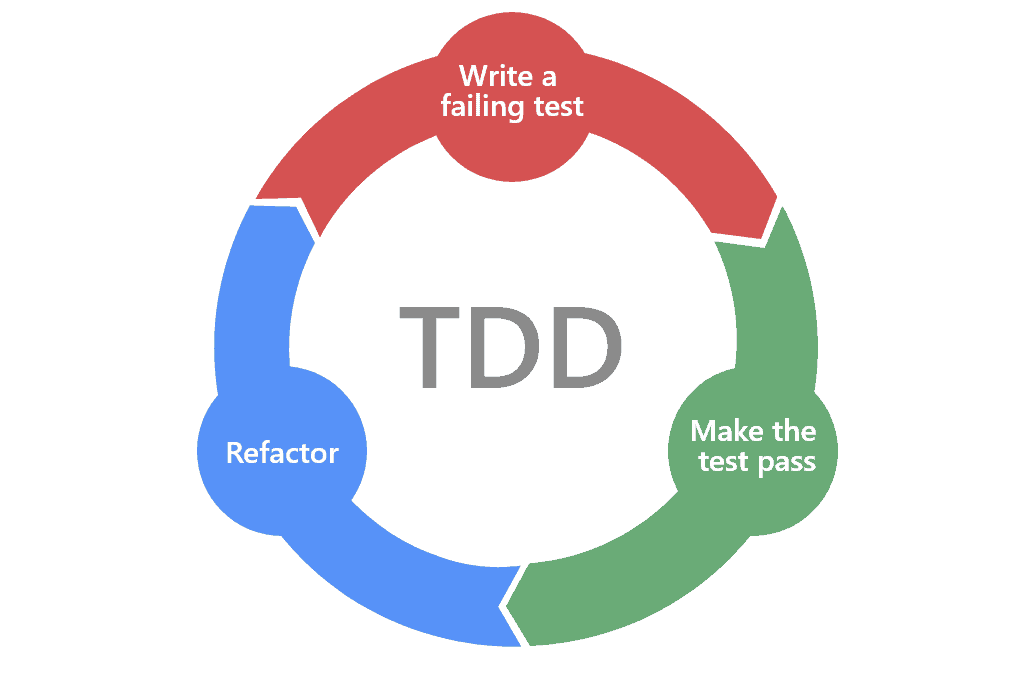 Ciclo del TDD - Imagen obtenida de https://marsner.com/blog/why-test-driven-development-tdd/
Ciclo del TDD - Imagen obtenida de https://marsner.com/blog/why-test-driven-development-tdd/
Una de las principales razones de porqué al momento de crear nuestro caso de prueba base (que debe fallar), debería ser enfocado en su API o comportamiento que este CUT ofrecerá al mundo exterior o componentes que interactuarán con el, es la capacidad de podernos centrar en los aspectos de alto nivel que brindan valor al sistema que deseamos construir, de tal manera que se comporte como esperamos se deba comportar desde una perspectiva más cercana al usuario. Estos aspectos de alto nivel (API) cambian con menor frecuencia que aquellos relacionados con su implementación, por lo tanto como ya mencioné anteriormente, pasan a un segundo plano otorgándonos la libertad de implementar estas caracterizticas como queramos. Es aquí donde se separan de una manera un poco más evidente una fase de diseño de una fase de codificación, y no quiero decir con esto que esta fase de codificación de la implementación no requiera diseño, es obvio percatarnos que si requiere diseño, me refiero al diseño a un alto nivel, separándólo de los detalles que no aportan por ahora mayor interés al comportamiento del sistema.
Al tomar esta aproximación enfocada en el API del sistema logramos hacer que el proceso de Refactorización se convierta en una de las fases mas entretenidas y fascinantes de aplicar TDD como metodología. La clave de esto es muy sencilla de evidenciar: Podemos cambiar cuantas veces queramos la implementación del código y nuestras pruebas deberán mantenerse estables y vigentes. Esto quiere decir, que al momento de realizar nuestra primera implementación para que la prueba pase, podemos evidenciar mas adelante durante el proceso de desarrollo que había una alternativa más eficiente o limpia de hacerla, sin el temor de romper nada, sin el ego de querer tenerlo todo limpio, mantenible, escalable y elegante en un principio.
Quiero abordar más a detalle algunos de los aspectos que he mencionado sobre estos temas en particular podremos hablar largo y tendido como se diría coloquialmente, pero para efectos de este post no será posible. Hazme saber si estás interezado en conocer más al respecto sobre esta metodología y muchas de sus características escenciales y lo que he podido aprender a lo largo de mi experiencia.
El objeto de hacer énfasis, para efectos de este post, en la metodología TDD y el concepto clave de ir evolucionando con el tiempo un sistema aparentemente complejo, es que, muchas veces subestimamos la capacidad que nos ofrece un aspecto escencial de esta metodología y es el proceso de Refactorización como ya he mencionado. Durante el proceso de implementación del proyecto del emulador de la NES, me he dado algunos caprichos bajo la premisa de: ¿Y por qué no? que me han permitido explorar diferentes caminos y maneras de hacer las cosas, guiados muchas veces por experimentaciones o situaciones problemáticas difíciles de preveer, que ocurren sobre la marcha, cuando me enfoco en aspectos muy particulares del sistema que deseo evolucionar.
Para evidenciar un poco mejor este aspecto, cuando inicié el proyecto de construcción de la NES, tenía marcada una línea de construcción definida, guiados por el entendimiento inicial que obteniamos de los aspectos generales de su funcionamiento. Por ejemplo, una vez concluida la implementación del core (CPU, ALU, Memoria e Instrucciones), se pretendía iniciar la construcción del componente PPU (Picture Processing Unit) encargada de mostrarnos en pantalla la representación gráfica de nuestros programas (ROMs). Cuando fue necesario ponerlo todo en conjunto y poner en marcha estos componentes con programas reales, se evidenciaron ciertas necesidades que en un principio no se contemplaban. Una de estas necesidades fue la de crear un componente Debugger (depurador) que nos permitiera indagar sobre aspectos particulares en momentos específicos de la ejecución de un programa o ROM, evidenciando así mismo, si nuestra CPU está ejecutando correctamente sus instrucciones demandadas. Este proceso se realiza ejecutando ciertas ROMs de prueba creadas por la comunidad de la NES para validar el correcto funcionamiento de los componentes escenciales de la consola. En nuestro caso pretendíamos probar el funcionamiento de la CPU y su juego de instrucciones oficiales.
Una vez construido el componente debugger, nos permitió interactuar de una manera un poco más sencilla, con los componentes core de la NES y su integración durante la ejecución de un programa real, permitiéndonos encontrar un par de bugs y evidenciando que en términos generales nuestra CPU y todas sus instrucciones se comportan correctamente.
Actualmente mientras escribo esta publicación, me encuentro implementando la UI para este componente debugger, que nos permita ejecutar ROMs y realizar pruebas de ejecución sin la necesidad de realizar pruebas de código, las cuales son insuficientes para ciertos casos en particular, dicho de otro modo, tendríamos nuestra primera cara visible del emulador, donde podremos probar con diferentes ROMs e inspeccionar múltiples aspectos de nuestros componentes internos y garantizar su fiabilidad. Adicionalmente, tendríamos un componente usable en términos de usuario del emulador, que nos permitirá comprobar funcionalidades particulares de los componentes construidos y por construir, que mediante pruebas de código implicaría un mayor esfuerzo. De esta manera, hemos descubierto una nueva necesidad, que un principio no era evidente, pero durante el proceso de construcción guíado por pruebas se fue conviertiendo en una herramienta clave para apoyarnos en el desarrollo de nuestro emulador, y por qué no, tambien como una herramienta externa de analisis para esta arquitectura que podríamos exponer a la comunidad a manera de agradecimiento 😎.
Anteriormente, me he referido al proceso de Refactorización un lujo, y es que si nos ponemos a pensar efectivamente corresponde a una actividad que muchos no podrán practicar en sus proyectos con la tranquilidad de no romper nada. Esto se debe principalmente a 2 razones: (1) Códigos base sin pruebas de código que permitan alertarnos ante cualquier novedad inesperada en los contratos establecidos por el sistema y (2) cuando enfocamos nuestras pruebas en los detalles de implementación y no en el comportamiento de nuestros componentes o API (aquello que pocas veces cambia), estamos permitiendo alojar pruebas de código frágiles, que al menor cambio de algún detalle en la implementación, tendremos que actualizar también la prueba de código.
Para nadie es un secreto que en muchos proyectos y procesos de desarrollo la fase de pruebas se convierte en un aspecto de métricas (coverage), más que en un aspecto de calidad, o peor aún, se considera el coverage como un aspecto de calidad, y por lo tanto nos encontramos con casos de prueba enfocados en cómo implementaremos X característica y bajo que patrones, principios o técnica ninja lo conseguiremos, llenando el proyecto de un montón de pruebas frágiles que a la menor necesidad de cambio explotarán y representarán una mayor inversión de tiempo en corregirlas, y mayor dinero requerido para llevar a cabo el proyecto; el inicio de muchos males.
Volviendo a los términos principales de esta publicación, dos de los caprichos que me he podido permitir en términos de refactorización o búsqueda de hacer mejor ciertas cosas, han sido: (1) incluir Typescript dejando a un lado el confort del Javascript vanila que me gusta tanto, y (2) solucionar un “problema” de manejo de dependencias entre los componentes core de la NES, que ha día de hoy están construidos, mediante la exploración de ciertas alternativas basadas en patrones de diseño y siendo estrictos con la evaluación de estas alternativas en términos del performance de estos componentes, que son el objeto central de esta publicación y que detallaremos más adelante.
A medida que el proyecto a ido creciendo en funcionalidades y componentes implementados, me he visto en la tarea de agrupar funcionalidades comunes en componentes que reflejen dichas intenciones, respetando de esta manera, en la medida de lo posible el principio de responsabilidad única (SRP Single Responsibility Principle), logrando un código un poco mas desacoplado entre sus partes (ya hablaremos de esto mas adelante) y mas cohesivo con sus responsabilidades.
Desde las primeras líneas de código escritas en el proyecto enfocadas en la construcción de la CPU y la implementación de sus caracteristicas principales guiados por el uso de la metodología TDD, se han ido descubriendo estas porciones de código que posteriormente se han convertido en componentes individuales con sus propias responsabilidades. Desde un punto de vista de alto nivel, algunos de estos componentes no existen en el mundo real (por lo menos de manera aislada físicamente) si queremos compararlos con aquellos componentes físicos de hardware que componen la NES, pero que al mismo tiempo nos permite mediante estas nuevas abstracciones que hemos identificado como necesarias, lograr un código base más desacoplado y testeable.
Al momento de crear esta publicación los componentes que hacen parte del core de la NES que han sido abstraidos durante el proceso de construcción son:
Ahora, si prestamos atención en los componentes principales que posee la NES, desde una perspectiva de hardware y aquellos componentes de interacción directa con la CPU, podremos evidenciar los siguientes.
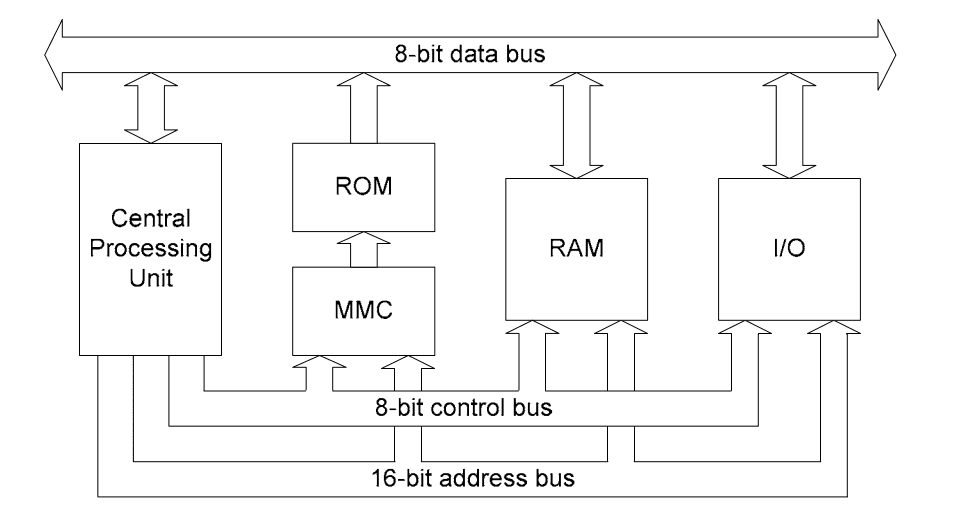 Diagrama del procesador - Imagen obtenida de https://www.nesdev.org/NESDoc.pdf
Diagrama del procesador - Imagen obtenida de https://www.nesdev.org/NESDoc.pdf
La imagen anterior nos muestra a un alto nivel, los componentes principales que interactúan con la CPU. También se puede observar algunos componentes que no han sido abstraidos por nuestro emulador, como lo son, el bus de direcciones, el bus de datos, los dispositivos de entrada y salida (I/O) y el bus de control, cuya abstracción de este último la obtendremos como resultado final de esta publicación. Nótese que el componente de la ALU no se encuentra presente en la imagen, debido a que este generalmente es un componente interno de la CPU. En nuestro caso hemos extraído estas funcionalidades específicas en nuestro propio componente separado.
Otro componente ausente por el momento de nuestra implementación del emulador, son los dispositivos de entrada y salida (I/O) que hace referencia a los Joysticks u otros dispositivos que han estado presentes para extender las funcionalidades de la NES como la Zapper gun por mencionar uno de los más populares.
Si deseas estar al tanto del proyecto del emulador de la NES, o quieres inspeccionar en detalle sus abstracciones, componentes, e implementaciones realizadas, lo podrás encontrar aquí: Repositorio de github: CaNES.
También, si deseas apoyarme regalándome una estrella ⭐ al repositorio, estaré muy agradecido.
Por otra parte el componente MMC que hace referencia a los mapeadores de memoria de la ROM, que vienen siendo algo como unos circuitos especiales presentes en los cartuchos de ROM para extender sus capacidades básicas, tanto en capacidad de memoria (programa y gráficos) como memoria RAM adicional como se presenta en algunos mappers específicos para la NES. Si alguna vez te preguntaste por qué algunos juegos tenían características adicionales como, niveles e historias extendidas (Super Mario Bros 3), capacidad de guardar progreso de las partidas (Legend of Zelda) entre otras tantas más, se debe principalmente a estos mapeadores de memoria, que extienden las capacidades básicas de la primera generación de cartuchos ROM de la consola.
Finalmente encontramos los buses de datos, dirección y control que a nivel de hardward son lineas específicas de conexión que interconectan los componentes de la NES para permitir la comunicación entre ellos, dicho de otro modo, son las vías de transporte de información necesaria para operar entre sí a un bajo nivel. Para efectos de la publicación no es necesario detallar los dos primeros, puesto que han sido omitidos en los procesos de abstracción del emulador, delegando estas responsabilidades a las caracteristicas del lenguaje Javascript (Typescript), como los argumentos de funciones, valores de retorno y operaciones básicas entre variables.
Lo que sí es necesario destacar de los componentes anteriores, es el bus de control, cuya función principal consiste en notificar o demandar operaciones de los otros componentes conectados a él. Nótese también que el componente que tiene mayor control sobre este bus (de donde se origina), es la CPU, de ahí que sea el cerebro de la NES. Por lo tanto podemos observar que mediante estas líneas de transporte, todos los componentes principales de la NES están interconectados de manera directa o indirecta.
A medida que se iban construyendo los componentes del emulador, una característica escencial para asegurar estas relaciones de “uso” entre componentes, fue la inyección de dependencias. Antes de incluir Typescript en el proyecto la forma en la que aseguraba este mecanismo era mediante la implementación del patrón módulo en Javascript. Aquí un ejemplo de como se veía el componente de la CPU utilizando este patrón.
/**
* branch: master
* commit: fda225c
* file: src/core/cpu/cpu.js
*/
export const CPU = () => {
...some stuff
const execute = (instruction) => {
instructions.execute(instruction)
_updateCtrl()
}
const debug = (_debugger) => {
nesDebugger = _debugger
_setDebugMode(true)
}
...some other functions
const cpuApi = {
debug,
execute,
... all other public functions
}
let rom = null
let nesDebugger = null
const cpuALU = ALU(cpuApi)
const instructions = Instructions(cpuApi, cpuALU)
const addressingModes = AddressingModes(cpuApi, cpuALU)
return cpuApi
}Haciendo uso de funciones básicas y los closures podíamos conseguir el objetivo que buscábamos de separar módulos o componentes del emulador, cada uno de ellos con su propia interfaz pública (API), con la característica adicional de poder inyectar dependencias según sea necesario como se observa en los módulos internos construidos por la CPU. Debo reconocer que este patrón es uno de mis favoritos cuando escribo Javascript puro incluso prefiero evitar usar la sintaxis de clases de ES6. Lo reconozco, me gusta ir por el camino con mayor resistencia, pero que me deja los mayores aprendizajes (que a fin de cuentas es lo que busco).
Como destaqué hace poco, una de las ventajas y cosas que más disfruto hacer en este proyecto es poder experimentar cualquier cosa sin temor a nada, y una de ellas (que sí medité bastante) fue incluir Typescript al proyecto, y volcarnos a un paradigma y forma de hacer las cosas un poco diferente, que nos abre también nuevas posibilidades. Aquí un ejemplo de como se ve el mismo componetne de la CPU pero ahora bajo las aguas de Typescript. Para ello nos ubicamos en un punto específico del historial, en este caso el commit 247528c.
/**
* branch: master
* commit: 247528c
* file: src/core/cpu/cpu.ts
*/
export class CPU implements NESCpuComponent {
private cpuState: CPUState = structuredClone(CPUInitialState)
private cpuExecutor: CPUExecutor | null = null
private cpuALU: NESAluComponent | null
private memory: NESMemoryComponent | null
private instruction: NESInstructionComponent | null
...some stuff
private constructor () {}
getComponents (): NESCpuComponents {
return {
cpuALU: this.cpuALU,
memory: this.memory,
instruction: this.instruction
}
}
...some stuff
private initComponents (): void {
this.cpuState = structuredClone(CPUInitialState)
this.cpuALU = ALU.create(this)
this.memory = Memory.create(this)
this.memory.initComponents()
this.instruction = Instruction.create(this)
}
static create (): NESCpuComponent {
const cpu = new CPU()
cpu.initComponents()
return cpu
}
}Bien, lo que pretendo destacar principalmente, es que la inyección de dependencias entre los componentes de la NES, es necesaria dada la naturaleza del mundo real de donde venimos abstrayendo estos elementos. Algunos de estos componentes que han sido creados mediante procesos de refactorización o extracción de responsabilidades a componentes independientes como el caso del componente ALU, Instruction y AddressingModes son dos ejemplos de abstracciones del emulador que no están visibles a nivel de hardware (placa base de la NES) pero que nos permite separar un poco más las responsabilidades de nuestros componentes y tener un código base un grado mayor de cohesión.
Podemos observar que en este punto del tiempo, nuestra CPU es el componente que hace el rol de padre o agregado para los demás componentes internos, gestionando su ciclo de vida así como sus dependencias, algo que puede tener sentido dada la importancia de la CPU como elemento principal de la NES, producto de los procesos de extracción de responsabilidades en componentes independientes, pero en este caso quizás ya se va evidenciando también la necesidad de extraer este enmarañado proceso de creación de componentes internos bajo una nueva abstracción que nos permita encapsular estos procesos.
El problema principal de por qué ya era necesario buscar esta nueva abstracción fue la inecesaria complejidad que tiene la CPU de conocer estas necesidades y relaciones de sus demás componentes internos, dicho de otro modo, en términos de hardware, la CPU no contiene el módulo de memoria en su interior. Aquí es dónde se evidencia la evolución de nuestro código mediante pruebas, que posteriormente nos conducen a tomar decisiones enfocadas en otros aspectos no funcionales y donde las nuevas abstracciones, patrones, código limpio, etc hacen su aparición en el proceso de refactorización.
Pero antes de continuar, véamos cual era ese problema subyacente en el enmarañado de las dependencias que en este momento administraba la CPU y como encapsulábamos un poco este proceso.
/**
* branch: master
* commit: 247528c
* file: src/core/cpu/cpu.ts
*/
export class CPU implements NESCpuComponent {
...some stuff
private constructor () {}
...some stuff
private initComponents (): void {
this.cpuState = structuredClone(CPUInitialState)
this.cpuALU = ALU.create(this)
this.memory = Memory.create(this)
this.memory.initComponents()
this.instruction = Instruction.create(this)
}
static create (): NESCpuComponent {
const cpu = new CPU()
cpu.initComponents()
return cpu
}
}Mediante el uso de un costructor privado y haciendo uso de un método fábrica podíamos asegurar que al momento de solicitar una instancia del módulo de la CPU desde el exterior, solo sea posible mediante este método create() el cual al momento de crear la instancia nos asegura que la inicialización de los demás módulos se ha realizado. En este caso opté por separar este proceso del constructor mediante el método initComponents() para reflejar un poco más clara la intención y facilitar la inclusión de hipotéticas precondiciones para la creación del módulo de la CPU y asegurar que los clientes del módulo no deban conocer estas necesidades. Este patrón también es implementado en cada uno de los componentes de la NES para abstraer estas complejidades en los módulos internos que estos puedan tener. Pero, ¿qué ocurre con el módulo memory?, su método initComponents es conocido por la CPU y no está encapsulado por el método create de su clase. Es correcto, aquí hay un problema que se hizo evidente a medida que íbamos creciendo el emulador de la NES.
En este caso particular para el módulo de memoria, si miramos un poco su constructor en este mismo punto del tiempo, vemos esto:
/**
* branch: master
* commit: 247528c
* file: src/core/memory/memory.ts
*/
export class Memory implements NESMemoryComponent {
private readonly cpu: MemoryCpu
private addressingModes: NESAddrModesComponent | null
private MEM = new Uint8Array(CPUMemoryMap.Size)
private constructor (cpu: MemoryCpu) {
this.cpu = cpu
}
initComponents (): void {
this.addressingModes = AddressingModes.create(this.cpu)
}
... other stuff
}Para resumir un poco esta problemática, el módulo de memoria internamente abstrae ciertas funcionalidades propias del acceso a la memoria mediante su propio módulo, en este caso AddressingModes, el cual se encargará de estas responsabilidades particulares, que por ahora no tiene caso mencionarlas. Lo importante aquí, es que esté nuevo componente, intentará acceder al componente memory mediante cpu (una señal más para abstraer) y realizar sus tareas; ahora, dado que el módulo de memoria construye y tiene control sobre este componente y aún nos encontramos sobre el proceso de creación de memory, este no estará conectado con cpu cuando AddressingModes sea construido. Lo sé es algo confuso pero nos quedaremos con el hecho que AddressingModes durante su proceso de creación necesita de memory dado que implementa algunos closures para exponer sus funciones y es aquí donde todo se revienta si no aseguramos que memory se encuentre vinculado de antemano con el componente cpu.
Otro problema que podemos destacar es el orden de creación de estos componentes, por ejemplo, si movemos la creación del componente Instructions de tal manera que se encuentre antes de la creación del módulo memory también reventarán las pruebas de código y nos alertarán de los problemas (punto a favor del testing con sentido).
Ya tenemos muchas problemáticas en el camino, y como he dicho, estamos en el punto donde no podemos seguir evolucionando sin antes cambiar esta situación mediante una nueva abstracción que nos encapsule todo esta red de dependencias y ciclos de vida de cada uno de los componentes, para evitar situaciones como laas previamente mencionadas.
La respuesta la podemos encontrar un poco en la imagen anteriormente expuesta sobre los componentes de la NES y su relación interna, uno de los componentes que allí destacan es el Bus de Control. Cuya responsabilidad es asegurar la relación entre los componentes interno y su comunicación por mencionar un par de sus responsabilidades. Ahora bien, si lo que quisiéramos en este caso es que el bus de control nos gestione la relación de dependencias entre los componentes internos (core) mediante un proceso de comunicación donde ninguno de estos componentes deba conocer sobre los demás componentes existentes, entonces una muy posible abstracción para este bus de control es implementar el patrón mediator.
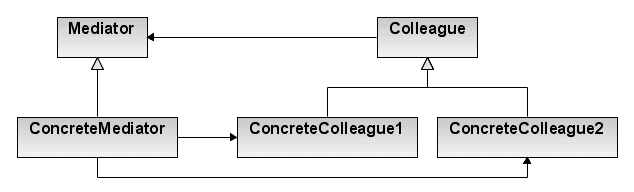 Patrón de diseño: Mediador - Imagen obtenida de https://en.wikipedia.org/wiki/Mediator_pattern
Patrón de diseño: Mediador - Imagen obtenida de https://en.wikipedia.org/wiki/Mediator_pattern
Patrón de diseño: Mediador - https://en.wikipedia.org/wiki/Mediator_pattern
La característica principal de este patrón es que nos permitirá desacoplar los componentes internos de la NES mediante la implementación de una única dependencia (bus de control) quien será la única capáz de conocer sobre los demás componentes y como se comunicarán entre sí. De tal manera que nos brinda una posible solución al caótico problema de las dependencias y sus ciclos de vida, así como una interfaz para comunicarnos con los demás elementos de la NES. El bus de control en este caso, será el mediador que sugiere el patrón para llevar a cabo estas responsabilidades, así que detallemos estas un poco mas:
Lo que nos dicen estas responsabilidades y el patrón mediador, es que el bus de control actuará como una clase fábrica administrando el ciclo de vida de los componentes internos y así mismo proveerá una interfaz común para garantizar la comunicación entre estos componentes. Para evidenciar un poco mejor, como se construyó el bus de control mediante el patrón mediador, existe una rama en el código del proyecto llamada feature/nes-control-bus que contiene toda la implementación que iremos detallando poco a poco durante la publicación.
Lo primero que debemos construir es la interfáz del bus de control que nos permitirá llevar a cabo las dos responsabilidades una vez la implementemos. Si nos encontramos ubicados en la rama feature/nes-control-bus podemos encontrar lo siguiente:
/**
* branch: feature/nes-control-bus
* commit: 8568cc8
* file: src/core/control-bus/types/index.ts
*/
... some stuff
export interface NESComponents {
cpu: NESCpuComponent
alu: NESAluComponent
instruction: NESInstructionComponent
memory: NESMemoryComponent
}
export interface NESControlBus {
getComponents: () => NESComponents
notify: (request: NESBusRequest) => void
request: <TResponse>(request: NESBusRequest) => TResponse
}Vemos que exponemos 3 métodos los cuales reflejan a un alto nivel las dos responsabilidades del bus de control (administrar dependencias y comunicación). Mediante el método getComponents() (), buscamos exponer a las capas superiores que se construyen sobre el core un mecanismo para poder acceder a los componentes requeridos de una manera más directa. Los métodos notify(...)y request(...) serán las dos puertas de entrada para la comunicación entre los componentes internos, dicho de otro modo, el método notify(...) será quien reciba notificaciones para ejecutar acciones particulares sin requerir respuesta al emisor y por otra parte el método request(...) será quien procesará las solicitudes de algunos componentes y devolverá el resultado de su solicitud. En este caso hacemos uso de tipos genéricos de typescript para asegurar los contratos entre emisor y receptor para que se entregue lo que el emisor espera recibir.
Ahora, es el momento para que todos los componentes internos de la NES que vimos anteriormente, dependan solo de este bus de control mediante su interfaz pública, y sin la necesidad de esperar a su implementación, asegurando que dependamos siempre de abstracciones y no de implementaciones como norma escencial.
// file: src/core/cpu/cpu.ts
export class CPU implements NESCpuComponent {
...
private constructor (private readonly control: NESControlBus) {}
...
static create (control: NESControlBus): NESCpuComponent {
return new CPU(control)
}
}// file: src/core/memory/memory.ts
export class Memory implements NESMemoryComponent {
...
private constructor (private readonly control: NESControlBus) {}
...
static create (control: NESControlBus): NESMemoryComponent {
return new Memory(control)
}
}En este punto, cada uno de estos componentes core de la NES dependen solo de la interfaz NESControlBus y es mediante está interfaz que se realizarán las comunicaciones con los componentes requeridos. Nótese que el componente memory ahora ya no dispone de un método initComponents() para gestionar sus dependencias internas, dado que esta responsabilidad recaerá ahora en el bus de control, haciendo que se pueda descartar, separando mucho más las responsabilidades de este componente y evitando la complejidad subyacente de este proceso como vimos anteriormente, un punto muy a favor del bus de control y la responsabilidad #1 que nos permite el patrón mediador. En el fragmento anterior solo mostré el componente cpu y memory, pero se da por entendido que todos los demás componentes respetan esta regla de dependencia única con el bus de control.
El siguiente paso para implementar este patrón mediador a través de un bus de control es identificar aquellas partes del código de cada uno de estos componentes core de la NES que realizen llamadas directas a otros componentes, y es allí, donde reemplazaremos estos fragmentos de código por una llamada al bus de control según sea el caso. Para notificar sin esperar ninguna respuesta usaremos notify(), y para solicitudes usaremos request(), enviando el cuerpo de cada una de estas solicitudes. Veamos un ejemplo.
En el componente cpu, podemos ver un ejemplo del uso de una comunicación con el bus del tipo notify(). Previo a la implementación del bus de control, en el método execute() , función que permite ejecutar una instrucción particular dado los bytes que la conforman, su implementación previa lucía así:
/**
* branch: feature/nes-control-bus
* commit: 247528c
* file: src/core/cpu/cpu.ts
*/
export class CPU implements NESCpuComponent {
...
execute (instruction: CPUInstruction): void {
this.instruction.execute(instruction)
this.updateCtrl()
}
...
}Aquí, la relación directa con el componente Instruction se reemplaza por los siguiente:
/**
* branch: feature/nes-control-bus
* commit: 8568cc8
* file: src/core/cpu/cpu.ts
*/
export class CPU implements NESCpuComponent {
...
execute (instruction: CPUInstruction): void {
this.control.notify({
type: NESBusRequests.Execute,
data: instruction
})
this.updateCtrl()
}
...
}Ahora, esta necesidad de conocer sobre el componente Instruction es delegada al bus de control y simplemente realizamos un llamado para notificar que el módulo cpu debe ejecutar una instrucción en particular, la cual será envíada en la carga útil de la solicitud. Adicionalmente hemos definido los tipos de solicitudes permitidas por el bus de control (que solo se evidenciarán en su totalidad en el proceso de eliminación de estas dependencias entre componentes) y una definición del cuerpo de las solicitudes con el tipo de carga útil, en caso de ser requerida.
/**
* branch: feature/nes-control-bus
* commit: 8568cc8
* file: src/core/control-bus/consts/bus-events.ts
*/
export enum NESBusRequests {
AddCPUExtraCycles = 'AddCPUExtraCycles',
Execute = 'Execute',
GetInstructionSize = 'GetInstructionSize',
...
}/**
* branch: feature/nes-control-bus
* commit: 8568cc8
* file: src/core/control-bus/types/index.ts
*/
... some other types
export type NESBusRequest =
| { type: NESBusRequests.GetPCRegister }
| { type: NESBusRequests.IsDebugMode }
| {
type: NESBusRequests.AddCPUExtraCycles
data: number
}
| {
type: NESBusRequests.Execute
data: CPUInstruction
}
|
... some other requests
}
... some other typesCon esto, el bus de control podrá indagar sobre el tipo de solicitud enviada por los componentes de la NES y realizar las funcionalidades específicas que hemos extraido de los componentes emisores, y será el propio bus quién realizará un forwarding de esta solicitud al componente responsable, así:
/**
* branch: feature/nes-control-bus
* commit: 8568cc8
* file: src/core/control-bus/control-bus.ts
*/
export default class ControlBus implements NESControlBus {
private readonly cpu: NESCpuComponent
private readonly alu: NESAluComponent
private readonly addressingModes: NESAddrModesComponent
private readonly instruction: NESInstructionComponent
private readonly memory: NESMemoryComponent
private readonly cpuState: CPUState
private constructor () {
this.cpu = CPU.create(this)
this.alu = ALU.create(this)
this.memory = Memory.create(this)
this.addressingModes = AddressingModes.create(this)
this.instruction = Instruction.create(this)
this.cpuState = this.cpu.getCPUState()
}
notify (request: NESBusRequest): void {
switch (request.type) {
... other cases
case NESBusRequests.Execute:
this.instruction.execute(request.data)
break
... other cases
}
}
... other stuff
static create (): NESControlBus {
return new ControlBus()
}
}Ahora, el bus de control realizará la solicitud al componente instruction enviando la carga útil recibida por el componente emisor cpu. Nótese también que ahora el bus de control es responsable del ciclo de vida de los componentes internos de la NES, y es de esta manera que hemos solucionado también el inconveniente de las dependencias circulares que hemos tenido en algunos componentes como memory y addressingModes . Al depender solo de la abstracción NESControlBus , el resto de componentes internos no necesitan saber sobre condiciones específicas del ciclo de vida de otros componentes y solo se entenderán con el bus de control.
Para aquellas solicitudes que requieren de una respuesta específica por parte de los componentes receptores, se ha implementado el método request() de la siguiente manera:
/**
* branch: feature/nes-control-bus
* commit: 8568cc8
* file: src/core/control-bus/control-bus.ts
*/
export default class ControlBus implements NESControlBus {
... other stuff
request<TResponse>(request: NESBusRequest): TResponse {
let response
switch (request.type) {
... other cases
case NESBusRequests.Load:
response = this.memory.load(request.data)
break
... other cases
}
return response as TResponse
}
... other stuff
}De esta forma haciendo uso de genéricos podemos establecer un contrato entre el componente emisor y receptor asegurando el tipo de los datos que serán devueltos por el bus de control hacia el componente emisor. En este caso, la función load() del componente memory permite obtener un valor específico de la memoria de la NES dada una dirección que será enviada como carga útil desde el componente que la necesita. Veamos un ejemplo de algún componente que hace uso de esta característica.
// file: src/core/cpu/components/addressing-modes.ts
export class AddressingModes implements NESAddrModesComponent {
... some stuff
private absolute (): CPUAddrModeHandler {
return {
get: (operand) =>
this.control.request<number>({
type: NESBusRequests.Load,
data: operand
}),
set: (value, memoryAddress) => {
... other stuff
}
}
}
... some stuff
}Al momento de enviar la solicitud, especificamos el tipo de dato de la respuesta y así establecemos la comunicación con el bus de control cuando deseamos obtener algún dato de los otros componentes internos de la NES. Entonces, las relaciones directas que teníamos entre componentes las extrajimos al bus de control y solo mediante el uso de los métodos notify() y request() nos entenderemos. Al finalizar dichas extracciones ningún componente interno tendrá una referencia a otro componente salvo el bus de control. TDD en estos casos y la base de pruebas con sentido que hemos construido a lo largo del desarrollo nos ayudan con la muy especial característica de asegurarnos de no romper nada durante esos procesos de experimentación o refactorización. Es hermoso, lo sé.
En consecuencia, hemos implementado un patrón de diseño convencional que nos ayuda a resolver las dos problemáticas mencionadas con anterioridad, generando una nueva abstracción que se encuentra muy bien definida en términos de hardware de la NES pero que solo fue necesaria hasta el momento de presentarse las necesidades particulares. A fin de cuentas, dichas abstracciones deben ser guiadas por estas necesidades y no al revés cuando muchas veces creamos abstracciones sin requerirlas por el afán de ser “clean coders”. Pero aquí hay algo más, este patrón si bien nos ha permitido la separación de preocupaciones, mediante una característica técnica específica, nos ha generado una preocupación más, que solo se evidencia cuando realmente conocemos las necesidades particulares de la NES: El perfomance.
Si bien conocemos de antemano y como lo mencioné al inicio de esta publicación, con la implementación de la metodología TDD podemos centrarnos en aspectos particulares del sistema sin la necesidad de conocer sobre los otros involucrados que gobiernan su funcionamiento, y hasta cierto punto esto es cierto, permitiéndonos enfocarnos en en las necesidades particulares y brindar una solución que cumpla con los requerimientos principales.
TDD no es una metodología que nos asegura el correcto desarrollo de nuestras necesidades, simplemente nos ofrece una vía segura de implementar lo que consideramos que debe ser implementado, en este caso implementar lo que la prueba nos dice que debamos implementar. Por lo tanto no es garantía que aquello que enmarcamos en una prueba como dicta la metodología este bien construida y orientada a la satisfacción de la necesidad real del sistema. Este punto es importante destacarlo, dado que a veces se mal interpreta a TDD como una metodología que nos permite desarrollar con cero bugs en el camino, y no es así, quien construye y diseña los casos de prueba es humano y los humanos tienden a equivocarse 🤗, implementando erróneamente un caso de prueba que nació erróneo. El conocer las necesidades nos evitará un poco más caer en este valle.
Volviendo al punto que nos interesa, cuando se inició el desarrollo del emulador y el conocimiento obtenido durante el proceso de entendimiento de las características de la NES, era evidente que había ciertos aspectos de bajo nivel que debían ser protegidos a medida que íbamos desarrollando, y para este caso estamos haciendo referencia al performance, atributo escencial en estos componentes de bajo nivel, en especial la CPU, aquella unidad por donde pasarán cientos de miles de instrucciones por segundo (dada su velocidad de reloj) y que al momento de realizar cambios escenciales en el código base que impacta estos elementos donde transcurre la acción de ejecutar las instrucciones, debemos ser cuidadosos y medir el impacto que puedan tener estos cambios en el código.
En lo personal, no soy alguien que disfrute memorizar patrones de diseño, términos y otros tantos elementos presentes en la actividad del desarrollo de software, si bien es importante conocerlos, quiero hacer énfasis en el hecho que muchas veces en el ejercicio de estas actividades, se comete el error de querer implementar cuanta herramienta o solución se nos presente en el camino o conozcamos de antemano, sin antes realizar un proceso de evaluación adecuado que guíe su elección cuando sean requeridas y enfocarnos de lo que realmente importa. Al momento de tener la necesidad latente de resolver el enmarañado de dependencias presentes en el emulador y orquestarlas mediante una solución práctica y elegante como fue el patrón Mediator (como otros tantos más), sabía que el añadir una nueva capa de abstracción al core de la NES impactaría negativamente en la velocidad con que nuestra CPU iba a ejecutar las instrucciones que le pasáramos, pero quería saber ¿Qué tanto?. Dicho de otro modo, ahora con esta nueva implementación que soluciona las dolencias previamente mencionadas, deberá ejecutar más instrucciones de código para garantizar la resolución de mensajes recibidos al mediador (Bus de Control), lo que se traducirá en una latencia adicional a la que ya teníamos presente.
La CPU tiene una velocidad de ejecución definida por su hardward en términos de velocidad de reloj, la cual determinará cuantas instrucciones por segundo podrá ejecutar, y esta velocidad deberá ser respetada si lo que queremos implementar es un emulador que sea fiel al comportamiento de los dispositivos de hardware que estamos desarrollando. Para el caso de la NES (versión americana de la Famicom), el chip que conforma la CPU, es el Ricoh 2A03, que es una implementación del chip MOS 6502, muy popular por estar presente en dispositivos de cómputo como la Apple II y la Commodore 64. La velocidad de reloj de este chip, es establecida en 1.789773 MHz, lo que sugiere que deberá tener 1,789,773 ciclos de reloj por segundo.
También debemos tener en cuenta que no todas las instrucciones que soporta la CPU demandan la misma cantidad de ciclos de reloj para su ejecución, dicho de otro modo, hay instrucciones que se ejecutarán en 6 ciclos de reloj, como otras más simples en términos de hardware que demandarán solo dos ciclos de reloj como el caso de la instrucción CLC. Otro aspecto técnico a destacar de esta CPU es que el mínimo de ciclos de reloj que demandará una instrucción será de 2 y hay instrucciones que demandan hasta 6 ciclos de reloj para ser ejecutadas en su totalidad, dependiendo de el modo de direccionamiento que esta utilice, como el caso de la instrucción ADC bajo el modo de direccionamiento (Indirect,X).
Si deseas conocer más sobre las instrucciones que soporta la CPU y sus particularidades, en este recurso podrás encontrar mayor información.
El modo de direccionamiento en términos simples, es la forma en que la CPU dicta de dónde extraerá los valores necesarios que serán los operandos de la instrucción que se desea ejecutar. Tanto de algún registro interno, la ROM o algúna porción específica de la memoria. Por lo tanto habrán instrucciones que tardarán más ciclos de reloj en ser ejecutadas que otras, dada la complejidad que pueda representar este proceso de extracción de valores.
Estos detalles técnicos nos ayudarán a comprender por qué el performance importa en una solución como la que deseamos construir, y es que debemos encargarnos de respetar estas equivalencias con el hardware real. Si prestamos atención por ejemplo, hay una instrucción, la ADC (ya mencionada previamente), con el modo de direccionamiento (Indirect,X), es una de las que más ciclos de reloj emplea para su ejecución, respecto a todo el juego de instrucciones oficiales de la NES (si, hay instrucciones no oficiales pero no es relevante detallar este aspecto).
Algo que suelo discutir en mi mente, y que afortunadamente (para mi) he empezado a compartir, como el caso de este post, es la idea de que todos los conceptos y principios de desarrollo de software como SOLID, Clean Code, DRY, Patrones de Diseño, etc, son la cuspide de un código bien escrito, cuando olvidamos por completo que estas herramientas son buenas bajo un contexto determinado, y dicho contexto lo define las necesidades del sistema. Por lo tanto cuando hablamos de acoplamiento por ejemplo y vemos un código base que tiene relaciones estrechas con otros componentes del sistema, esto ya nos huele mal y de primeras lo tachamos de código mal escrito, porque estamos complicando los posibles escenarios donde este código base puede ser mantenido, extendido, extraído, y tantas más actividades que moldean muchos de los principios que hoy conocemos y son la ley.
Para el caso que nos compete en nuestro emulador de la NES, la CPU y los demás componentes que hacen parte del core del sistema, deberán actuar y realizar sus acciones lo más rápido dentro de lo permitido. Dicho de otro modo entre más acoplamiento tengamos será mucho mejor. Y si se que puede sonar extraño decirlo, pero nuestro contexto así lo determina. Entre menos capas de abstracción incluyamos en el core mejor será. Esto nos hace suponer que muchas veces olvidamos ese requerimiento no funcional llamado rendimiento, que en términos prácticos si importa, y mucho, y las prácticas de código limpio, patrones de diseño o prácticas determinadas, nos impactan de manera negativa este factor en muchas ocasiones.
No quiero decir con esto que los principios y técnicas mencionadas no logren un buen código que sea elegante de llevar con el paso del tiempo. Me refiero más bien a la tarea nuestra como desarrolladores de código de poder evaluar los contextos donde nuestra aplicación se mueve y bajo que necesidades estamos construyendo, y esto es algo que muchas veces se olvida o se pierde porque estamos guiando una práctica de desarrollo de software por las tendencias en términos de prácticas y herramientas que son relevantes a dia de hoy. Sin embargo, la naturaleza de un software exige un poco más que eso, y es esa capacidad de nosotros para poder ir quizás un poco en contra de los estándares, por el bien de nuestra solución y es algo que requiere carácter.
Retomando la pregunta que buscaba responder de, ¿Que tanto impactará el implementar una nueva capa de abstracción al core de nuestro emulador?, el planteamiento más cercano para buscar dicha respuesta fue medirlo. No soy experto en realización de benchmarks, de hecho este es mi primer benchmark realizado a una solución de software y lo que pretendo realizar es comparar en términos simples un estado anterior sin la nueva capa de abstracción (patrón mediator) y el nuevo estado con la implementación deseada.
El objetivo del benchmark será hacer uso de forma standaolne de la CPU y ejecutar todo el set de instrucciones disponibles. Recordemos que hay una cantidad de ciclos por segundo presentes en la CPU en términos de hardware que hay que respetar y por ende una cantidad de instrucciones por segundo que también debe mantenerse. Por ejemplo, si tomamos una instrucción que tarde 2 ciclos de reloj en ejecutarse al completo, si suponemos que la cpu solo ejecutara esta instrucción indefinidamente, deberá ejecutar un número de 894886,5 veces (1789773 Velocidad del reloj / 2 Ciclos por instrucción), y para el caso de una instrucción que tarda 6 ciclos de reloj en ejecutarse, el número de veces será 298295,5 (1789773 Velocidad del reloj / 6 Ciclos por instrucción).
Lo anterior, nos muestra como podríamos plantear el escenario para nuestro benchmark. Si al ejecutar el script la CPU va a ejecutar una instrucción que tarda 6 ciclos de reloj en ser ejecutada, el script la ejecutará tantas veces como sea necesario para un segundo, como vimos en los cálculos previos. Posteriormente registrará el tiempo que tardó en ser ejecutada esa cantidad de veces y ese será el tiempo que usaremos como referencia para cada una de las instrucciones que soporta nuestra CPU.
Para efectos del post no explicaré en detalle la implementación del script, pero puedes echarle un vistazo en el código del proyecto en la rama feature/nes-control-bus mencionada previamente dónde se encuentran las implementaciones realizadas que detallamos en este post. A modo de breve resumen, el script lo que hará es pasar cada una de las instrucciones, con sus respectivos operandos al método execute() que expone la CPU y ejecutará la cantidad de veces requeridas para tal instrucción en un fragmento de segundo de acuerdo a la cantidad de ciclos que esta tarda. Los resultados serán almacenados por instrucción y se descartarán tanto el menor como el mayor de 6 intentos y posteriormente se listarán en orden descendente de acuerdo al tiempo que han tardado en ejecutarse. Aquí un fragmento del código:
/**
* branch: feature/nes-control-bus
* commit: 8568cc8
* file: tests/benchmark/instructions/strategies.ts
*/
export function executeAverageOnInstructionCycles (config: BenchmarkStrategyConfig): [time: number, timesExecuted: number] {
const TIMES_TO_RUN = 6
let times = []
let executedTimes = 0
for (let i = 0; i < TIMES_TO_RUN; i++) {
const [time, numOfExecutions] = executeByInstructionCycles(config)
executedTimes = numOfExecutions
times.push(time)
}
// Removes the maximus and minimum times
times = times.sort((a, b) => b - a)
.slice(1, times.length - 1)
const totalTime = Math.round(times.reduce((acc, prev) => acc + prev, 0) / (TIMES_TO_RUN - 2))
return [totalTime, executedTimes]
}Para ejecutar el benchmark simplemente ejecutamos el script de npm benchmark:average, el cual nos permitirá realizar múltiples ejecuciones y promediarlas como detallé. Terminado de ejecutar el benchmark veremos en la terminal los resultados tabulados de manera descendente, así:
$ npm run benchmark:average
...
Running: [AVERAGE] Benchmark to run the basic benchmark multiple times and average it.
Instruction Time Times Executed
sbc (IndirectIndexed) 444 ms 357955
adc (IndirectIndexed) 435 ms 357955
cmp (IndirectIndexed) 375 ms 357955
lda (IndirectIndexed) 367 ms 357955
and (IndirectIndexed) 355 ms 357955
eor (IndirectIndexed) 353 ms 357955
ora (IndirectIndexed) 344 ms 357955
adc (Immediate) 320 ms 894887
... más isntrucciones
sei (Implied) 68 ms 894887
clv (Implied) 67 ms 894887
cld (Implied) 67 ms 894887
clc (Implied) 52 ms 894887
beq (Relative) 49 ms 894887
bcs (Relative) 48 ms 894887
nop (Implied) 28 ms 894887
jmp (Absolute) 20 ms 596591
Summary: 26.943 seconds.El resultado que nos muestra el benchmark, lejos de ser un benchmark perfecto, nos dice muchas cosas en lo que al emulador respecta. Por ejemplo, nos brinda la visibilidad de cuales instrucciones tardan mayor tiempo en ejecutarse como el caso de sbc (IndirectIndexed) y cuantas veces esta instrucción sería ejecutada (columna Times Executed) si el procesador solo ejecutara este tipo de instrucción y por último, cuanto tiempo tardó en mi máquina con mis especificaciones de hardware, en realizar estas ejecuciones (columna Time).
También nos brinda la posibilidad de priorizar acciones de refactorización desde un punto de vista de mejora continua de nuestro código base orientado a la mejora del rendimiento en la ejecución de instrucciones por parte de la CPU e identificar con mayor claridad cuales pueden ser los posibles cuellos de botella que afectan este atributo. Por último y quizás el factor que nos trajo hasta este punto es responder la pregunta de que tanto nos afecta el rendimiento el incluir una solución al problema de dependencias y comunicación entre componentes expuesto con anterioridad. Para ello debemos establecer el punto comparativo entre ambos escenarios, con, y sin la implementación, entonces, podemos ejecutar nuevamente el script pero esta vez ubicados en la rama principal master en el commit 30d1dea apartir del cual incluí la implementación del script de benchmark para ser utilizado en las nuevas evoluciones, es decir, que ubicados en ese commit podemos ejecutarlo sobre la implementación que no posee la solución del bus de control. Ahora bien, si ejecutamos el script ubicados allí obtenemos lo siguiente:
$ npm run benchmark:average
...
Running: [AVERAGE] Benchmark to run the basic benchmark multiple times and average it.
Instruction Time Times Executed
sbc (IndirectIndexed) 353 ms 357955
adc (IndirectIndexed) 341 ms 357955
cmp (IndirectIndexed) 304 ms 357955
and (IndirectIndexed) 294 ms 357955
lda (IndirectIndexed) 294 ms 357955
eor (IndirectIndexed) 293 ms 357955
ora (IndirectIndexed) 287 ms 357955
sbc (ZeroPage) 246 ms 596591
... más instrucciones
cli (Implied) 50 ms 894887
bne (Relative) 47 ms 894887
bcc (Relative) 46 ms 894887
beq (Relative) 40 ms 894887
bcs (Relative) 39 ms 894887
clc (Implied) 37 ms 894887
nop (Implied) 28 ms 894887
jmp (Absolute) 18 ms 596591
Summary: 21.015 seconds.
Son datos y hay que darlos diríamos coloquialmente, y es que es evidente la latencia que hemos añadido comparando la instrucción que más tarda en ser ejecutada en cada uno de los dos resultados del benchmark, al rededor de 100ms para el caso de la instrucción sbc (IndirectIndexed). Esta instrucción en particular con su modo de direccionamiento debe realizar varias acciones de consulta de datos con el componente Memory para efectuar su responsabilidad, y por lo tanto, al implementar un mediador que responda a sus solicitudes la latencia es algo natural en este tipo de soluciones, que si bien brindan una solución a unos problemas particulares, impactan negativamente otros, y es el trade-off natural de las decisiones que debemos tomar cuando desarrollamos software.
Pero, ¿por qué es importante la latencia en este módulo de la CPU si el benchmark nos muestra que todas las instrucciones han sido ejecutadas en menos de 1 segundo como debería ser de acuerdo a los planteamientos anteriores?
Cuando desarrollamos aplicaciones para el navegador, hay ciertos aspectos que no pueden ser pasados por alto y que deben operar en conjunto con las necesidades del emulador que estamos desarrollando como también es en nuestro caso. Para no ahondar en más detalles técnicos, los navegadores web como brave, chrome, firefox, etc, siempre intentarán en la medida de lo posible y que el código de la aplicación se lo permita también, realizar un renderizado de las vistas que vemos en ellos enmarcados en 60 cuadros por segundos (fps), es decir, cada vez que vemos una página que no contiene mayor código javascript en ejecución y que no este peleando y reclamando atención de recursos, es muy posible que esta página web hipotética cumpla con esta métrica.
Tomando como base lo anterior, hay un objetivo latente que debe ser cumplido tambien por nuestro emulador, y es asegurar los 60fps si queremos aferrarnos a los estándares actuales, o los 30fps aproximados, bajo el estándar de televisión análoga NTSC, en el cual operaba la consola. Por lo tanto si tomamos como base los resultados del benchmark si queremos asegurar en su totalidad el cumplimiento de estos requisitos, debemos estar siempre en la medida de lo posible por debajo del umbral de 1000ms por instrucción.
También hay algo que juega a favor nuestro y es que en un escenario real y no sintético como el expuesto en el benchmark, los programas no estarán compuestos por un solo tipo de instrucción claramente, y los casos de estas instrucciones que demandan más ciclos de reloj y por ende tardan mas en ser ejecutada suelen ser menos frecuente, por tareas de optimización de los desarrolladores de los cartuchos ROM de la NES, allí, bajo la escasez de recursos, las optimizaciones si importaban, y mucho.
Ahora bien, cuando nuestra CPU ejecute las instrucciones que ha de ejecutar en una ROM real en un segundo, el tiempo que esta tarde en realizar su trabajo, debe ser inferior como ya vimos a 1000ms de tal manera que haya un espacio entre el tiempo que demora la CPU en hacer su trabajo y el tiempo que otros componentes como la PPU (Picture Processing Uniti) encargada de renderizar y mostrar lo que el programa desea mostrar, bajo una métrica de 60fps o los 30fps según decidamos más adelante. Es aquí entonces donde debemos priorizar cualquier milisegundo que logremos obtener de tareas de optimización y así mismo evitar añadir latencias inecesarias que impacten a estos requerimientos que deberan ser implementados más adelante, y que tendremos que pelear por asegurar que los navegadores web nos brinden las imágenes renderizadas por nuestro emulador bajo estas métricas.
Por lo tanto, la conclusión a la que nos lleva todo lo anterior, es la de descartar la implementación de un bus de control, que nos gestione la comunicación entre componentes, centralizando este proceso y evitando el acoplamiento que este promueve entre los componentes involucrados. Pero también, si prestamos atención de dónde surgieron estas abstracciones que hemos desarrollado de los componentes, su naturaleza de hardware refleja también un acoplamiento en el sentido que algunos componentes o chips en este caso, por ejempo el de la CPU, tiene conexión directa con otros elementos de la placa base, para demandar o notificar acciones relevantes a otros componentes, y es evidente, que no hay un elemento que orqueste estas comunicaciones de manera centralizada, sino que cada uno de los componentes establecerá una conexión directa con aquellos elementos de su interés. El rendimiento es crucial en este punto y no se puede permitir añadir latenciaas o retardos inecesarios, y lo mismo haremos nosotros.
 Placa base de la NES - Imagen obtenida de https://es.m.wikipedia.org/wiki/Nintendo_Entertainment_System](https://es.m.wikipedia.org/wiki/Nintendo_Entertainment_System
Placa base de la NES - Imagen obtenida de https://es.m.wikipedia.org/wiki/Nintendo_Entertainment_System](https://es.m.wikipedia.org/wiki/Nintendo_Entertainment_System
Nota: Si bien he mencionado que no hay un elemento central que administre la comunicación entre todos los componentes de la NES, si hay un master clock, que en términos simples, es responsable de determinar en que fragmentos de tiempo deben ocurrir cada una de las tareas de cada componente interno y gobierna así mismo el reloj interno de la CPU y la PPU por ejemplo.
Este último aspecto que he mencionado lo he dejado para lo último porque no representa una excusa formal de por qué hicimos lo que hicimos, si no más bien de cómo la naturaleza de lo que estamos construyendo tiene conocimiento directo de otros componentes mediante estas líneas de conexión directa. Lo que buscamos como desarrolladores de aplicaciones es encontrar aquellas abstracciones que se ajusten mucho mejor a las necesidades que reclama la solución, y en este caso tener un código acoplado, visto de manera negativa como ya mencionamos, es lo que nos permite seguir operando con un rendimiento que debemos asegurar a lo largo del desarrollo del proyecto, y abriendo camino a las nuevas implementaciones de los demás componentes que demandan un pedacito del pastel que en este caso, la CPU ya tomó el suyo.
Para cerrar, debo decir que el acoplamiento que tienen estos componentes en el emulador, lo veo hermoso, por el simple hecho que nos evitamos abstracciones inecesarias y vamos al grano con lo que demanda cada componente, interpretando estas comunicaciones de manera directa y sin tapujos como lo hace el hardware real. El acoplamiento ganó esta batalla 😎
Por último quiero rescatar y recordar que el bus de control que fue planteado para solucionar la comunicación entre los componentes, no tenía como única responsabilidad cumplir con esto, sino también nos permitió solucionar el problema de las dependencias mediante una abstracción simple que no impacta el comportamiento de los componentes internos, como sí lo hacía el patrón mediador y cualquier otro patrón de comportamiento que pueda haber en el mercado.
De esta manera, la implementación actual del emulador incluye la abstracción NESControlBus, que actúa como centro de fábrica orquestando el ciclo de vida y las dependencias entre los componentes mediante un único componente (el ControlBus), en un nivel superior que no impacta el funcionamiento interno de cada uno de ellos, mediante una conexión directa sin intermediarios, entre un componente y otro.
/**
* branch: master
* commit: ed98987
* file: src/nes/core/control-bus/control-bus.ts
*/
export default class ControlBus implements NESControlBus {
private readonly _cpu: NESCpuComponent
private readonly _alu: NESAluComponent
private readonly _addressingModes: NESAddrModesComponent
private readonly _instruction: NESInstructionComponent
private readonly _memory: NESMemoryComponent
private constructor () {
this._cpu = CPU.create(this)
this._alu = ALU.create(this)
this._instruction = Instruction.create(this)
this._addressingModes = AddressingModes.create(this)
this._memory = Memory.create(this)
}
getComponents (): NESComponents {
return {
cpu: this.cpu,
alu: this.alu,
instruction: this.instruction,
memory: this.memory
}
}
get cpu (): NESCpuComponent {
return this._cpu
}
... more getters
static create (): NESControlBus {
return new ControlBus()
}
}Y si observamos ahora como se realiza esta comunicación mediante el bus de control, si bien todos los componentes ahora solo dependen de este, seguimos estando acoplados en el sentido que la comunicación la hacemos de manera directa y debemos conocer los componentes con los que interactuaremos, así:
/**
* branch: master
* commit: ed98987
* file: src/nes/core/cpu/cpu.ts
*/
export class CPU implements NESCpuComponent {
... other stuff
private constructor (private readonly control: NESControlBus) {}
execute (instruction: CPUInstruction): void {
this.control.instruction.execute(instruction)
this.updateCtrl()
}
... other stuff
}Por lo tanto, el bus de control se convierte en el elemento orquestador de todos los componentes del core del emulador, y permite una via de comunicación directa y no centralizada entre estos (la ley de Demeter, no es ley en estas tierras ✌🏽), sin añadir mecanismos elaborados de mensajeria que impactan el performance negativamente. Para este caso el script del benchmark no se ve afectado en comparación con la implementación previa sin el bus de control, debido a que solo establecimos relaciones mas no comportamientos nuevos, y es ahora dicho benchmark quién conducirá muchas de las decisiones que tomemos sobre el core del emulador.
He escrito largo y tendido, pero a decir verdad he disfrutado el proceso de escribir cada una de estas palabras, y si eres uno de aquellos que llegó hasta aquí, así sea por conocer un poco de las ideas, formas de pensar y ver las cosas que tengo relevantes al desarrollo de software, te agradezco muchísimo por tomarte tu tiempo de hacerlo.
Todo lo que he escrito no es para nada una ley que pretendo establecer a todo tipo de aplicación, o que tú como desarrollador debas aplicarlas también en tus proyectos, sino más bien, son casos específicos donde las cosas que hicimos tuvo una razón que nos guió a ellas y quizás tú como lector, puedas encontrar otras muchas más y que mejor se comporten a como las he implementado en el proyecto del emulador de la NES. Si así es el caso me encantaría conocer que otras alternativas puedo aplicar a los casos mencionados y como hacer que convivan con los requerimientos del proyecto, también si consideras que he cometido algún error en lo previamente mencionado, estaré a gusto de saberlo para corregirlo, déjame saberlo, en algunos de los medios que tengo disponibles.
Finalmente, me gustaría mencionar algunas de las máximas que a mi modo de ver son las partes escenciales que quise transmitir con este escrito:
Nota final: Actualmente me encuentro en búsqueda de empleo, y si tú como lector, conoces de alguna oportunidad, donde pueda hacer parte para resolver como ingeniero de software, estaré muy agradecido en compartirme cualquier información al respecto, en los canales de comunicación que tengo disponibles.
Mil gracias de antemano. ♥️

